After inadvertently finding that InfoSys leaked an AWS key on PyPi I wanted to know how many other live AWS keys may be present on Python package index. After scanning every release published to PyPi I found 57 valid access keys from organisations like:
- Amazon themselves 😅
- Intel
- Stanford, Portland and Louisiana University
- The Australian Government
- General Atomics fusion department
- Terradata
- Delta Lake
- And Top Glove, the worlds largest glove manufacturer 🧤
This post outlines the way I scanned PyPi, showcases a project I’ve built that automatically scans all new PyPi releases to notify AWS of potentially leaked keys, presents some analysis of the keys I’ve found and draws a few conclusions at the end.
How?
Detecting AWS keys is actually fairly simple. A keypair consists of two components: the key ID and the key secret.
The key ID can be detected with the regular expression ((?:ASIA|AKIA|AROA|AIDA)([A-Z0-7]{16})), and the secret key
can be detected with a much more general [a-zA-Z0-9+/]{40}. We can tie these together to find “key IDs close to secret keys, surrounded by quotes”
with this monster regex (regex101):
re.match(r"""
(('|\")((?:ASIA|AKIA|AROA|AIDA)([A-Z0-7]{16}))('|\").*?(\n^.*?){0,4}(('|\")[a-zA-Z0-9+/]{40}('|\"))+|('|\")[a-zA-Z0-9+/]{40}('|\").*?
(\n^.*?){0,3}
('|\")((?:ASIA|AKIA|AROA|AIDA)([A-Z0-7]{16}))('|\"))+
""")We can use the amazing ripgrep to search packages for this pattern:
$ wget "https://files.pythonhosted.org/.../amazon_pay-2.5.1.tar.gz"
$ rg --text -z --multiline $chonky_regex amazon_pay-2.5.1.tar.gz
2195:# mws_access_key='AKIAJIUGYOGHT2ONMCOQ',
2196:# mws_secret_key='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',And then we can try these keys with the aws CLI tool. If this returns a value then we’ve got a valid set of credentials!
$ AWS_SECRET_KEY=X AWS_ACCESS_KEY_ID=Y aws sts get-caller-identity
{
"UserId":"985141293874",
"Account":"985141293874",
"Arn":"arn:marketplacewebservice:iam::985141293874:root"
}The devil is in the details though - the -z flag doesn’t support searching zip files, so we need to use a custom shell
script to handle this, and there are some nuances around extracting the matches (using the JSON output) etc.
Once overcome, we can combine this a static dump of pypi data to run the whole
pipeline in parallel like so:
# Illustrative example, reduced in complexity quite a bit
$ git clone https://github.com/orf/pypi-data.git
$ fd -t f --min-depth=2 . 'release_data/' | parallel --xargs jq 'to_entries[] | .value.urls[].url' > all_urls.txt
$ cat all_urls.txt | parallel -I@ "wget @ -O downloads/@ && rg --json -z --multiline $chonky_regex downloads/@" > matches.txtThis took ~27 hours to run on my macbook using my home internet connection.
Automatically scanning new packages with Github Actions
I took the process outlined above and converted it into a Rust tool: https://github.com/orf/aws-creds-scanner
This tool runs periodically via Github Actions and sca ns new releases from PyPi, HexPM and RubyGems for AWS keys. If there are any keys found then a report is generated and committed to repository.
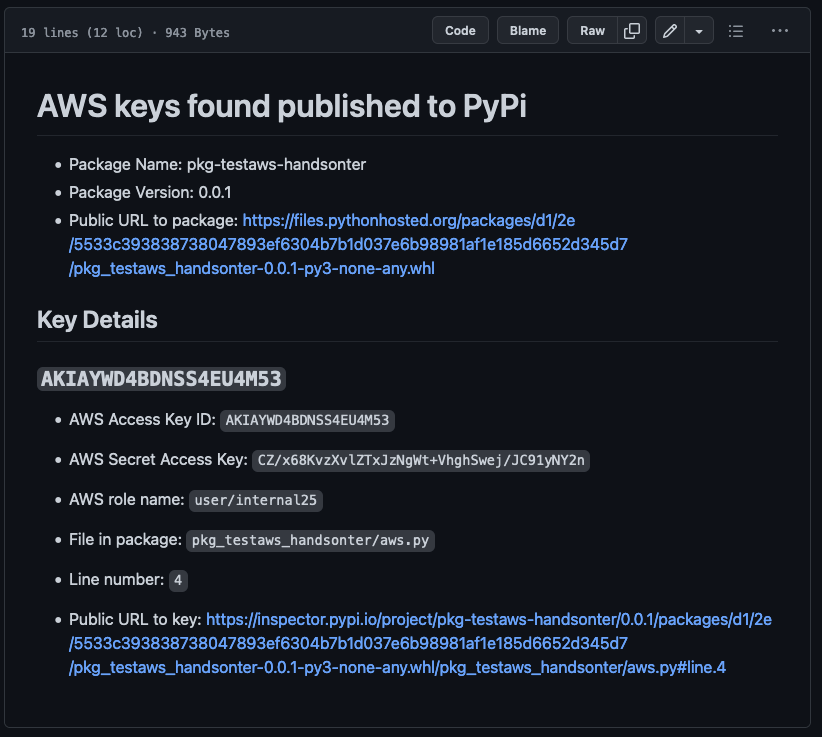
This report contains the keys that have been found, as well as a public link to the keys and other metadata about the release. Because these keys are committed to a public Github repository, Github’s Secret Scanning service kicks in and notifies AWS that the keys are leaked.
This causes AWS to open a support ticket with you to notify you of the leak, and apply a quarantine policy on the key to prevent some high-risk actions from being taken (i.e starting EC2 instances, adjusting permissions, etc).
Running a rust tool every half an hour via Github Actions isn’t exactly a web-scale solution to the problem, but it’s an effective “post-proof-of-concept” that is pretty cost effective ($0!). Rather than use a database to keep track of packages that have been processed Github Actions commits a JSON file keeping a kind of cursor to the last package it has processed. Subsequent invocations fetch the next set of packages after this cursor.
I quite like this pattern - it’s not perfect and does not handle individual package failures well, but it works quite nicely for periodic tasks like this.
Analysis of the leaked keys
The oldest still active key was uploaded nearly 10 years ago in 2013, and the newest one was published on the 20th of December.
Key Types
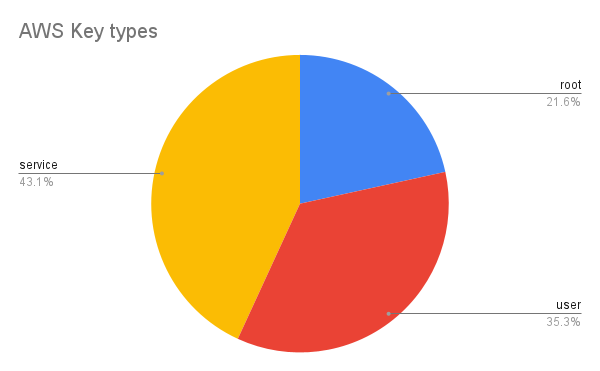
By looking at the name of the principal the key belongs to I attempted to categorize the type of key:
- Root (e.g
arn:aws:iam:..:root): 11 - User (e.g
arn:aws:iam:..:user/ivan.vasquez): 18 - Service (e.g
arn:aws:iam:..:user/S3TempUploader): 22
Types of leaks
Key leaks seem to be broken down into three categories: Accidentally committed files/changes, Test data/test files and “Legitimate” usage.
Accidentally published files
Authors of Python libraries can push different platform-specific files for each version they release. Tensorflow has 16 different versions for different Windows, Linux and MacOS versions. While usually these releases all contain exactly the same code, differences are possible.
One example comes from a package version published by Terradata.
The file containing the key, presto-local/debug, does not exist in the source version
and only exists in the platform-specific .egg releases.
It seems that while publishing a release, some files where accidentally bundled before publishing. This implies the release was not fully automated.
Amazon themselves fell victim to this: the amazon_pay SDK version 2.5.1
contains an accidental integration test that the developer was working on. This file is not present in previous or
future releases. There are other examples of mistakenly added integration tests,
one from a third party Amazon SDK.
Test files
12 of the 57 keys appear to be included as part of a test suite. These are usually in the form of integration test credentials.
DeltaLake added keys to their tests, but later refactored it to use LocalStack.
Other tests are a mix of “accidentally published files” and ad-hoc integration tests, like this file-level test.
Most test keys are used with S3, but there was one specific test from BigJob2 that appears to launch an EC2 instance 😱.
”Legitimate” usage
There are some packages that attempt to use long-lived IAM keys for “legitimate” uses. I put legitimate in quotes here, as there are much better ways to allow public access to specific AWS resources that don’t involve shared IAM keys.
The majority of these “legitimate” usages involve uploading temporary files to S3.
One example comes from Sym, an access management company.
They include some write-only IAM credentials and
apparently use it because their API is unable to generate temporary signed URLs yet.
Another example in the same vein comes from mootoo.
QuantPanda is a funny example of this. In version 0.0.22 to 0.0.25 the AWS key was hardcoded. However, after AWS flagged their key they switched from hard-coding the key to fetching it from a Gist 🙈:
aws_cred_df = pd.read_csv(r'https://gist.githubusercontent.com/ashishongari/eaf6cdede399ad0b2f0696d13982b374/raw/144b2034d49a4c28bbfbd478732de1f35de76b50/aws_cred_df.csv')
aws_access_key_id, aws_secret_access_key = aws_cred_df['aws_access_key_id'].iloc[0], aws_cred_df['aws_secret_access_key'].iloc[0]$ curl https://gist.githubusercontent.com/ashishongari/eaf6cdede399ad0b2f0696d13982b374/raw/144b2034d49a4c28bbfbd478732de1f35de76b50/aws_cred_df.csv
aws_access_key_id,aws_secret_access_key
AKIA5LQDGW3AUXC4RDHM,2U0GQ8PQKvwSkiSwBOJrYZRmGpGlHfQtFkoG5EWsI guess some people really don’t want to use short-lived credentials?
Conclusions
I found a lot more keys than I was expecting. Why? I think there’s a conflux of different reasons that have led to the large number of keys published to PyPi:
- Testing against AWS is hard. It is often simpler to just test against AWS themselves than set up moto or localstack.
- It’s easy to accidentally commit files when publishing releases. Python tooling could add an “are you sure” prompt if anything you’re publishing has not been fully committed to git.
- Python allows multiple individual downloads for a given release. Combined with point 2, this makes it easy to publish a “correct” release, make some changes and publish a sneakily incorrect one without realising.
- Python is used heavily for data-science and ML. A lot of the packages I found where around this domain, and perhaps best practices around AWS key management are not clear to those practitioners?